Fine-Tune Large Language Models(LLMs)
Natural language processing has undergone a transformation thanks to large language models (LLMs), which exhibit remarkable abilities and innovative solutions. These models, trained on vast amounts of textual data, perform exceptionally well in generating text, translating languages, summarizing content, and answering questions. However, despite their strengths, LLMs may not always be perfectly suited for specialized tasks or specific domains.
In this article, we will delve into how fine-tuning large language models (LLMs) can greatly enhance their performance, lower training costs, and provide more precise and context-specific outcomes.
When discussing fine-tuning, it's crucial to understand the parameters of the model. A model is essentially a network composed of weights and biases, which are the parameters. In any neural network, there are inputs, outputs, and hidden layers. Each node within these layers has associated weights and biases, which collectively define the parameters of the model. Fine-tuning involves adjusting these parameters to improve the model's performance on specific tasks.
A neural network is the cornerstone of deep learning. Whether it's an RNN, CNN, ANN, or transformer, neural networks are responsible for learning. In these networks, weights and biases are crucial components that we always aim to update during the learning process. To update these weights and biases, which are collectively referred to as parameters, we use various optimizers such as gradient descent, Adam, and RMSprop. These fundamental optimizers adjust the parameters to enhance the model's performance.
.png)
What is Fine-tuning?
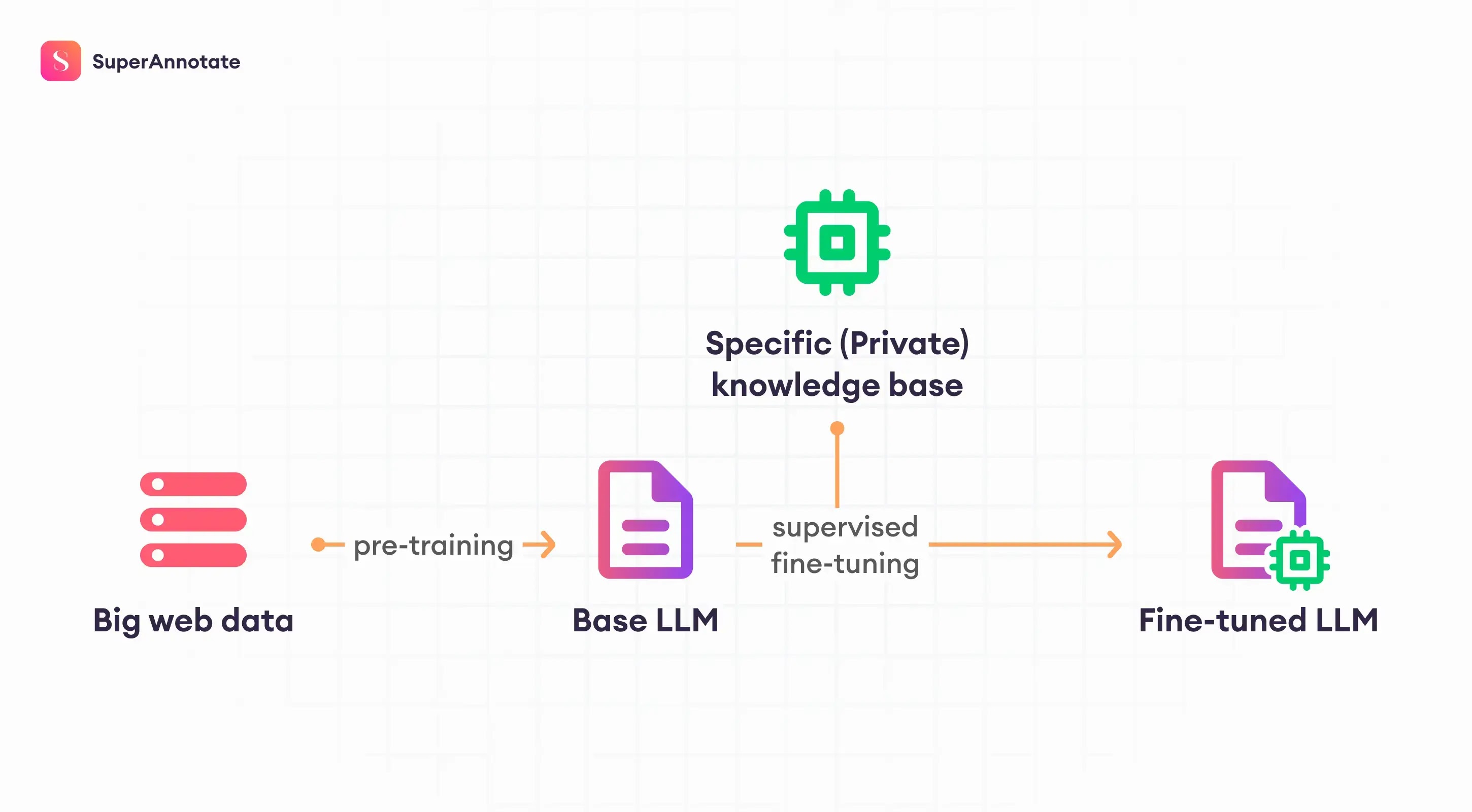
Fine-tuning is the process of taking a pre-trained model and making minor adjustments to its parameters to improve its performance on a specific task or dataset. This involves training the model on a new, often smaller, dataset that is closely related to the target application. By fine-tuning, the model can leverage its existing knowledge while adapting to the nuances of the new data, resulting in more accurate and context-specific outcomes. Fine-tuning is particularly useful for saving time and computational resources compared to training a model from scratch.

Let's say we have a model with three hidden layers, an input layer, and an output layer. Consider two people, Ram and Shyam. Ram wants to train a model to classify data into four classes: cat, dog, donkey, and tiger. He sets up the model with four output nodes, one for each class. After training, Ram's model has learned specific weights and biases, and it works well for his classification task.
Shyam, working in the same industry, has a similar task but only needs to classify data into two classes. To save resources, Shyam asks Ram for his pre-trained model. Ram saves the model, including the weights and biases, in an H5 file and gives it to Shyam. Shyam loads the model, modifies the output layer to have only two nodes, and uses the pre-trained weights. This process is called transfer learning.
Later, Shyam receives an updated dataset with six classes: cat, dog, donkey, monkey, lion, and tiger. He attempts to use the previous model, which has an output layer designed for only four classes. This architecture is insufficient for the new dataset. While the network can identify cats and dogs, it fails to recognize lions and monkeys because it hasn't been trained on these classes. Although the model captures some high-level features, it misses out on the low-level specifics needed to identify the new classes. To address this, Shyam needs to retrain the layers.
Initially, Shyam changed only the output layer, but now, with six classes, he must retrain the entire network, including the hidden layers, by updating the weights and biases. This process is fundamental to fine-tuning.
Fine-tuning involves adjusting the model's weights and biases based on specific requirements. It is crucial because it allows the model to adapt to new data and perform better on specialized tasks. Fine-tuning is essential in the current world to ensure models remain accurate and relevant as data and tasks evolve.
Impact of Fine-tuning in Industry:
In the realm of Recurrent Neural Networks (RNNs), we have various architectures such as standard RNNs, LSTMs (Long Short-Term Memory networks), GRUs (Gated Recurrent Units), Encoders & Decoders, and Attention mechanisms. These architectures are designed to handle different tasks such as language translation, summarization, classification, and text generation. These tasks are fundamental to language models, enabling them to understand, process, and generate human language effectively.
When training models for specific tasks, such as language translation, the model learns weights and biases that are tailored to that task. For instance, an LSTM model trained for machine translation might not perform well for summarization, because its weights and biases are optimized for translation rather than summarization. This limitation poses a challenge for transfer learning in RNN-based models in NLP.
To address this, the ULMFiT paper introduced a solution: it demonstrated that you can train NLP models in a way that allows them to be versatile across different tasks. ULMFiT utilized a technique called unsupervised pre-training, where a model is first trained on a large amount of data for a general task, such as next-word prediction. This approach helps the model learn to handle long contexts and develop a broad understanding of language.
This pre-trained model, capable of handling a variety of tasks, is known as a foundational model. The initial stage of this training is referred to as unsupervised pre-training. Once we have a foundational model, we can adapt it to specific tasks through fine-tuning, which involves adjusting the weights and biases to meet particular requirements. This process makes it possible to use the same model architecture for different tasks, leveraging the general knowledge acquired during the pre-training phase.
Types of Fine-Tuning Techniques:
When discussing large language models (LLMs) like GPT, LLaMA, and Gemini, which have parameters numbering in the billions—such as GPT-3 with 175 billion parameters, LLaMA with 70 billion, and Mistral with 7 billion—it's clear that adjusting all these parameters directly during training or fine-tuning is computationally intensive and resource-demanding.
Fine-tuning such massive models requires significant computational resources, including powerful GPUs or TPUs, and extensive memory. Because adjusting billions of parameters is not feasible for most users due to these high demands.

to solve above challenges researchers introduced different streamlined overview of the techniques used for optimizing large language models (LLMs), focusing on various fine-tuning and optimization methods:
Supervised Fine-Tuning
Supervised Fine-Tuning or Instruction Fine-Tuning involves retraining an entire pre-trained model, such as a GPT model with 70 billion parameters, on a specific task using labeled data. This method requires adjusting all weights and biases to adapt the model for new tasks, like conversational models. However, this approach is computationally expensive and time-consuming due to the extensive resources needed for retraining all parameters.
Parameter Efficient Fine-Tuning (PEFT)
To address the resource challenges of full fine-tuning, Parameter Efficient Fine-Tuning (PEFT) focuses on updating only a subset of the model's parameters. This method reduces computational costs and resource usage. Two key techniques in PEFT are:
LoRA (Low-Rank Adaptation): This technique introduces low-rank matrices into specific layers of the model, allowing for efficient updates to a small set of parameters while keeping the rest of the model unchanged.
QLoRA (Quantized Low-Rank Adaptation): A variant of LoRA that combines low-rank adaptation with quantization, further reducing the computational overhead and memory usage by working with quantized weights.
Reinforcement Learning through Human Feedback (RLHF)
Reinforcement Learning through Human Feedback (RLHF) adjusts the model's weights and biases based on human feedback. This approach involves training the model to optimize its performance according to human evaluations, making it more aligned with specific user requirements and improving its overall effectiveness.
Quantization
Quantization is a technique that reduces the precision of the model’s weights, such as converting floating-point numbers (e.g., 1.254678) to integer values (e.g., 1). By decreasing the bit-width of weights (e.g., from 64-bit to 16-bit or 8-bit), quantization lowers computational requirements and speeds up matrix operations, making the model more efficient.
Direct Performance Optimization (DPO)
Direct Performance Optimization (DPO) involves optimizing the model’s performance directly by adjusting specific parameters or aspects of the model to enhance its accuracy and efficiency. This technique aims to fine-tune the model's performance without extensive retraining.
These methods collectively enable the efficient use of large models, making it feasible to apply advanced language models in real-world scenarios with manageable computational resources and costs.
In conclusion, fine-tuning allows models to adapt to new tasks efficiently by leveraging pre-trained knowledge while focusing on task-specific adjustments. Techniques like PEFT, RLHF, quantization, and DPO make this process more resource-efficient, enabling the practical application of large language models across various domains.
Comments
Post a Comment